


Next: Categorization of Nuclei
Up: Prior Knowledge
Previous: Advantage of the new
The general idea for categorizing elements is to use specific contexts which point out some of the distributional properties of the category.
The categorization is a sequential process.
First the nuclei have to be found out.
For each tag of the corpus, we apply the function
 (equation 2).
This function selects a list of elements which are categorized as nuclei.
The function
(equation 2).
This function selects a list of elements which are categorized as nuclei.
The function
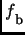 is then applied to this list in order to figure out nuclei which are breakers.
Then the adjuncts are found out, and the function
(equation 3 and 4) is also applied to them to figure out breakers.
is then applied to this list in order to figure out nuclei which are breakers.
Then the adjuncts are found out, and the function
(equation 3 and 4) is also applied to them to figure out breakers.
Since the corpus does not contain information about these distributional categories, ALLiS has to figure them out.
We do not want to introduce them into data since we still want to compare our approach with others using the same data.
This categorization relies on the distributional behavior of the elements, and can be automatically achieved using unsupervised learning.
We now explain how elements are categorized into these new sub-categories.
Subsections
Hammerton J.
2002-03-13