Lemma D.1 (Corollary
4.3)
Assume that the environment is such that

for all

. Let

be a prescribed number. For sufficiently large

and sufficiently small time steps, the SDS controller
described in Equation
10 and the environment form an
-MDP.
Proof.
From [
Szepesvári et al.(1997)] it is known that for
sufficiently fine time steps, the eventual tracking error is
bounded by

, i.e., for sufficiently large
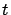
,
For sufficiently large
,

. Therefore for arbitrary value function

we may write
This means that the system is indeed an
-MDP.




