


Next: Classification with mixtures of
Up: Density estimation experiments
Previous: The ALARM network
For the third density estimation experiment, we used a subset of 576
images from a normalized face images dataset [Philips, Moon, Rauss, Rizvi
1997].
These images were downsampled to 48 variables (pixels) and 5
gray levels. We divided the data randomly into  and
and
 examples; of the 500 training examples, 50 were left out
as a validation set and used to select
examples; of the 500 training examples, 50 were left out
as a validation set and used to select  and
and  for the MT and
MF models. The results in table 5 show the mixture of
trees as the clear winner. Moreover, the MT achieves this performance
with almost 5 times fewer parameters than the second
best model, the mixture of 24 factorial distributions.
Note that an essential ingredient of the success of the MT both here and
in the digits experiments is that the data are ``normalized'', i.e., a
pixel/variable corresponds approximately to the same location on the
underlying digit or face. We do not expect MTs to perform well on
randomly chosen image patches.
for the MT and
MF models. The results in table 5 show the mixture of
trees as the clear winner. Moreover, the MT achieves this performance
with almost 5 times fewer parameters than the second
best model, the mixture of 24 factorial distributions.
Note that an essential ingredient of the success of the MT both here and
in the digits experiments is that the data are ``normalized'', i.e., a
pixel/variable corresponds approximately to the same location on the
underlying digit or face. We do not expect MTs to perform well on
randomly chosen image patches.
Table 5:
Density estimation results for the mixtures of trees and other models
on a the FACES data set. Average and standard deviation over 10
trials.
| Model |
Train likelihood |
Test likelihood |
| |
[bits/data point] |
[bits/data point] |
Mixture of trees
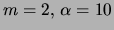 |
52.77  0.33 0.33 |
56.29 1.67 |
Mixture of factorials
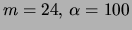 |
56.34 0.48 |
64.41 2.11 |
| Base rate |
75.84 |
74.27 |
| gzip |
- |
103.51 |
Next: Classification with mixtures of
Up: Density estimation experiments
Previous: The ALARM network
Journal of Machine Learning Research
2000-10-19