


Next: The SPLICE dataset: Classification
Up: Classification with mixtures of
Previous: The AGARICUS-LEPIOTA dataset
This data set contains 12,958 entries [Blake, Merz
1998], consisting
of 8 discrete attributes and one class variable taking 4
values1. The data were randomly separated into a training set
of size
 and a test set of size
and a test set of size  . In
the case of MTs and MFs the former data set was further partitioned
into 9000 examples used for training the candidate models and 2000
examples used to select the optimal
. In
the case of MTs and MFs the former data set was further partitioned
into 9000 examples used for training the candidate models and 2000
examples used to select the optimal  . The TANB and naive Bayes
models were trained on all the 11,000 examples. No smoothing was used
since the training set was large. The classification results are shown
in figure 14(b).
. The TANB and naive Bayes
models were trained on all the 11,000 examples. No smoothing was used
since the training set was large. The classification results are shown
in figure 14(b).
Figure:
Comparison of classification performance of the MT and other models on
the SPLICE data set when
 . Tree
represents a mixture of trees with
. Tree
represents a mixture of trees with  , MT is a mixture of trees
with
, MT is a mixture of trees
with  . KBNN is the Knowledge based neural net, NN is a neural
net.
. KBNN is the Knowledge based neural net, NN is a neural
net.
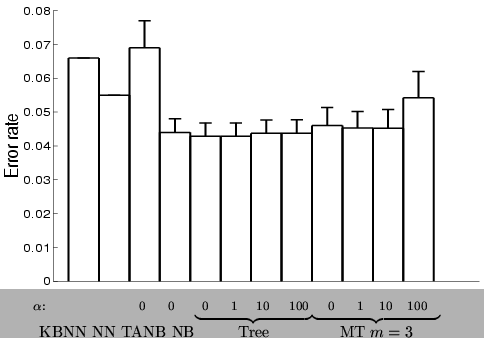 |
Figure:
Comparison of classification performance of the mixture of trees and
other models trained on small subsets of the SPLICE data set. The models tested by DELVE are, from left to right: 1-nearest neighbor, CART, HME (hierarchical
mixture of experts)-ensemble learning, HME-early stopping, HME-grown,
K-nearest neighbors, LLS (linear least squares), LLS-ensemble learning,
ME (mixture of experts)-ensemble learning, ME-early stopping.
TANB is the Tree Augmented Naive Bayes classifier,
NB is the Naive Bayes classifier, and
Tree is the single tree classifier.
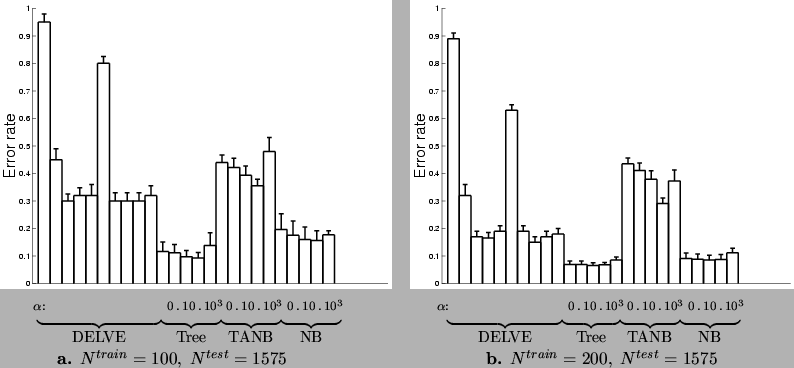 |
Next: The SPLICE dataset: Classification
Up: Classification with mixtures of
Previous: The AGARICUS-LEPIOTA dataset
Journal of Machine Learning Research
2000-10-19