


Next: Error Analysis
Up: Learning Rules and Their
Previous: Second Experiment: Using Prior
Shared Task CoNLL'00
Table 10 presents the complete results of the shared task of CoNLL'00 (chunking).
The task itself and the data are described in [Sang(2000a)].
ALLiS provides state-of-the art results.
All the systems do not use exactly the same features, in particular the size of the left context varies from three words (ALLiS), five in [Sang(2000b)], six in [Koeling(2000)], until eight in some cases in [van Halteren(2000)].
A comparison using exactly the same context would discriminate more properly the different approaches.
We can note that, even with the smallest context (three word), ALLiS performs better than some systems with larger contexts like Maximum Entropy used in [Koeling(2000)].
Note also that three out of four systems performing better than ALLiS use a system combination or voting approach.
The only ``simple'' system performing better than ALLiS is the one using the Support Vector Machine [, see][]svm_conll00.
They use a context of two words after and before the current word, a context larger than this used by ALLiS, but they also add in the left context information about the chunk tag.
This information is dynamically computed during the tagging step since the chunk tags are not given by the test data.
Such information can not be currently used by ALLiS, and its integration would require a modification not implemented for the time being, but scheduled.
Experiments done by others participants show that this information improves results.
[Nerbonne et al.(2001)Nerbonne, Belz, Cancedda, Déjean, Hammerton,
Koeling, Konstantopoulos, Osborne, Thollard, and Tjong Kim Sang] presents other systems that were applied on based-NP chunking.
We can note that ALLiS outperforms decision tree, well known for handling noisy data [, see][]Quinlan_86.
Table 10:
CoNLL'00 shared task: chunking
| test data |
precision |
recall |
F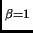 |
| Kudoh and Matsumoto |
93.45 |
93 51 |
93.48 |
| Van Halteren |
93.13 |
93.51 |
93.32 |
| Tjong Kim Sang |
94.04 |
91.00 |
92.50 |
| Zhou, Tey and Su |
91.99 |
92.25 |
92.12 |
| ALLiS |
91.87 |
92.31 |
92.09 |
|---|
| Koeling |
92.08 |
91.86 |
91.97 |
| Osborne |
91.65 |
92.33 |
91.64 |
| Veenstra and Van den Bosch |
91.05 |
92.03 |
91.54 |
| Pla, Molina and Prieto |
90.63 |
88.25 |
85.76 |
| Johansson |
86.24 |
88.25 |
87.23 |
| Vilain and Day |
88.82 |
82.91 |
85.76 |
| baseline |
72.58 |
82.14 |
77.07 |
|
Subsections
Next: Error Analysis
Up: Learning Rules and Their
Previous: Second Experiment: Using Prior
Hammerton J.
2002-03-13