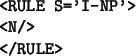Next: The Search Space
Up: The ALLiS Algorithm
Previous: Representation of the Data
Rule Generation and Evaluation
ALLiS generates a set of rules using the general-to-specific approach.
It starts with the most general rule and specifies it until its accuracy is high enough.
The purpose of a rule is to categorize a node with the attribute S, called the current node of the rule, the other nodes occurring in it are called the contextual nodes.
If one still uses the preceding example (learning NP), the initial rule is:
This first initial rule tags as I-NP (feature S of the rule) a node
without specificities (so all nodes). The quality of the rule is
then estimated. We just use its accuracy:
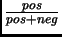 where
pos is the number of positive examples and neg the
number of negative examples covered by the rule. Positive examples of
the rule correspond to data that match the rule where the current node
is tagged S=I-NP. Negative examples correspond to data that
match the rule where the current node has not the feature
S=I-NP. This simple measure, the accuracy, is also used in
several other systems: [see][]Simaan97,Dagan98. Other
functions are proposed in the literature, for example the Laplacian
expected error [see][]Whisk. If the accuracy of a rule
r is greater than a given threshold called hereafter
where
pos is the number of positive examples and neg the
number of negative examples covered by the rule. Positive examples of
the rule correspond to data that match the rule where the current node
is tagged S=I-NP. Negative examples correspond to data that
match the rule where the current node has not the feature
S=I-NP. This simple measure, the accuracy, is also used in
several other systems: [see][]Simaan97,Dagan98. Other
functions are proposed in the literature, for example the Laplacian
expected error [see][]Whisk. If the accuracy of a rule
r is greater than a given threshold called hereafter
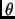 , r is judged reliable enough and is added into the
set of rules. is then a core parameter of the system.
Section 3 will show its influence on the system.
, r is judged reliable enough and is added into the
set of rules. is then a core parameter of the system.
Section 3 will show its influence on the system.
In the case of our initial rule, its accuracy is of course very low, since this rule is underspecified.
The next step of the general-to-specific algorithm is to add it literals in order to increase its accuracy.
We choose a new literal, C, which is added to the rule, creating new potential rules.
One new rule is created for each different value of the new literal.
Here are two new rules among other possibilities:
<RULE S='I-NP'>
<N C='NN'/>
</RULE>
<RULE S='I-NP'>
<N C='IN'/>
</RULE>
...
Each of these new rules is evaluated and specialized if necessary.
The first rule, which tags nouns (C='NN') as being part of an NP, is accurate enough (0.98), and is then validated.
<RULE NUM='1' ACC='0.98' FREQ='29027'>
<N C='NN'/>
</RULE>
The accuracy of the rule is not equal to 1 and it generates errors.
Section 2.4 will explain how these errors can be reduced thanks to the notion of refinement.
The second rule (C='IN') has to be specified, and new literals are added.
This generates rules such as:
<RULE NUM='39' S='I-NP' ACC='1.00' FREQ='2'>
<N W='about' C='IN'/>
<N C='$' RIGHT='1'/>
</RULE>
The tag RIGHT means that this node is a right contextual node of the rule.
This rule matches the sequence about $, and in this context, the word about belongs to an NP according to the training data.
No refinement is required since the refinement of the rule is 1.
The next section explains how new literals are selected.
Next: The Search Space
Up: The ALLiS Algorithm
Previous: Representation of the Data
Hammerton J.
2002-03-13