


Next: Representation of the Data
Up: Learning Rules and Their
Previous: Introduction
The ALLiS Algorithm
ALLiS is a classical top-down induction system.
The general algorithm is presented in Algorithm 1.
Top-down induction is a generate-then-test approach: a set of potential rules is generated according to some patterns, and each of them is tested against the training data.
Those being accurate enough are kept, the others deleted.
Section 2.3 explains how the set of potential rules is generated.
Whenever a new rule is learned, the bit of data covered by it is removed, and the process continues with the next rule.
Starting with the most general definition of a rule, ALLiS constrains it by adding new constraints (hereafter called literals) until its accuracy reaches a given threshold.
Like other induction systems, ALLiS does not guarantee that the set of rules is optimal.
If a comparison is drawn between our algorithm and those presented in the literature [see][]Mitchellbook,Quinlan90, the general architecture is very similar.
The major modification concerns the stopping criteria: whenever a rule is learned, ALLiS tests whether exceptions to this rule can be learned as well.
This process, which we call refinement, is described in detail Section 2.4.
When most algorithms learn a set of (ordered) rules, ALLiS learns a structured set of rules.
With each rule is explicitly associated a set of exceptions.
As the result will show, the accuracy of the structure (rule 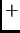 {exceptions}) is generally greater than the accuracy of the single rule itself (Section 2.4).
{exceptions}) is generally greater than the accuracy of the single rule itself (Section 2.4).
Why learning exceptions?
The main motivation of the introduction of this mechanism is to deal with noise.
The specific attention placed on handling noise is not only due to real noise in the data, but also due to the presence of exceptions in the language itself (or more exactly in linguistic theories used for annotating data) (Section 2.4).
Note that other inductive systems such as FOIDL [, see][]Califf95 or TBL [, see][]Brillcl also need to introduce such a mechanism when they are applied to linguistic data (for example, learning past tense of English verbs).

The kind of rules ALLiS learns is categorization rules: we try to categorize each element into the proper category.
Problems have then to be reformulated as categorization problems.
An example of a rule learned by ALLiS is:
<RULE NUM='98' S='I-NP' ACC='0.95' FREQ='175'>
<N C='DT' LEFT='1'/>
<N C='VBG' />
</RULE>
This rule is to be read: if a word tagged VBG (C='VBG') is preceded by a word tagged DT, then its category is I-NP (inside an NP, see Section 3).
The rule also contains information about itself: one unique identifier (NUM), its frequency (FREQ), its accuracy (ACC).
In the next sections, we detail first the data and representation used, and then each important step of the algorithm, the more important being the refinement step, the others being quite traditional.
Subsections
Next: Representation of the Data
Up: Learning Rules and Their
Previous: Introduction
Hammerton J.
2002-03-13