The formalism used by ALLiS in order to encode training data is XML.
Even if other representation schemas can be equivalently used (such as database formalism), XML offers an adequate representation allowing structured (here hierarchical) data encoding.
Data is then encoded in a tree structure.
For each sentence a node ![]() is created and for each word of the sentence an empty node
is created and for each word of the sentence an empty node ![]() .
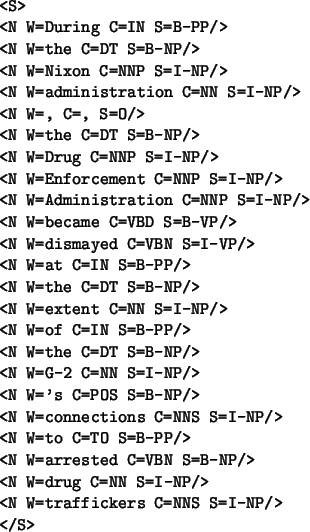
With each node is associated its features (in the following examples, the word itself (feature W), its POS-tag (feature C) and its category (S)).
This is a traditional attribute-value representation.
More complex annotation can be used, for example, the tree of a given linguistic analysis can be kept.
Table 1 shows data with a flat structure, and Table 2 with several linguistic hierarchical levels of information (chunk, clause).
We use the first representation for the CoNLL 200 shared task, and the second one was used for the CoNLL2001 shared task [see][]Dejeanclausing.
.
With each node is associated its features (in the following examples, the word itself (feature W), its POS-tag (feature C) and its category (S)).
This is a traditional attribute-value representation.
More complex annotation can be used, for example, the tree of a given linguistic analysis can be kept.
Table 1 shows data with a flat structure, and Table 2 with several linguistic hierarchical levels of information (chunk, clause).
We use the first representation for the CoNLL 200 shared task, and the second one was used for the CoNLL2001 shared task [see][]Dejeanclausing.
We now explain how positive and negative examples are generated from this annotation.
The division of the data into positive and negative examples is done thanks to the features.
For instance, let the example shown Table 1 be the complete training data and let NP chunking be the task.
The task is then to assign the correct value of the feature S to each node by using the features W and C.
Each node (word) with the features S='I-NP' or S='B-NP'1 is then a positive example, and each node without his feature is a negative example.
For example, the node ![]() N W=dismayed C=VBN S=I-VP/
N W=dismayed C=VBN S=I-VP/![]() is a negative example, when the node
is a negative example, when the node ![]() N W=arrested C=VBN S=B-NP/
N W=arrested C=VBN S=B-NP/![]() is a positive example, although both are tagged VBN.
This example shows that the information attached to each node may be insufficient in order to correctly recognize the attribute S.
Section 2.3 explains how the search space is extended.
is a positive example, although both are tagged VBN.
This example shows that the information attached to each node may be insufficient in order to correctly recognize the attribute S.
Section 2.3 explains how the search space is extended.