A disadvantage of the Gain Ratio metric used in memory-based learning is that it computes a weight for a feature without examining other available features. If features are dependent, this will generally not be reflected in their weights. A feature that contains some information about the classification class on its own, but none when another more informative feature is present will receive a non-zero weight. Features which contain little information about the classification class will receive a small weight but a large number of them might still overrule more important features. These two problems will have a negative influence on the classification accuracy, in particular when there are many features available.
We have tested the capacity of Gain Ratio to deal with irrelevant features by using it for a simple binary classification problem with extra random features. The problem which we chose is the XOR problem. It contains two binary (0/1) features and a pair of these feature values should be classified as 0 when the values are equal and as 1 when the features are different. We have created training and test data which contained 100 examples of the four possible patterns (0/0/0, 0/1/1, 1/0/1 and (1/1/0). A memory-based learner which uses Gain Ratio was able to correctly classify all 400 patterns in the training data. After this we added ten random binary features to both the training data and the test data and observed the performance. The average results of 1000 runs can be found in Figure 1.
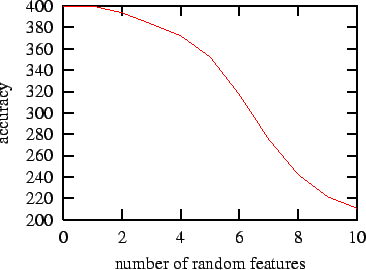 |
Without extra features the memory-based learner performs perfectly. Adding a random feature does not harm its performance but after adding two the system only gets 394 of the 400 patterns correct on average. The performance drops for every extra added feature to about 211 for 10 extra features which is not much better than randomly guessing the classes. This small experiment shows that Gain Ratio has difficulty with feature sets that contain many irrelevant features. We need an extra method for determining which features are not necessary for obtaining a good performance.
[Aha and Bankert(1994)] give a good introduction to methods for selecting relevant features for machine learning tasks. The methods can be divided in two groups: filters and wrappers. A filter uses an evaluation function for determining which features could be more relevant for a classifier than others. A wrapper finds out if one feature is more important than another by applying the classifier to data with either one of the features and comparing the results. This is requires more time than the filter approach but it generates better feature sets because it cannot suffer from a bias difference which may exist between the evaluation function and the classifier [John et al.(1994)].
Both the filter and the wrapper method start with a set of features and attempt to find a better set by adding or removing features and evaluating the resulting sets. There are two basic methods for moving through the feature space. Forward sequential selection starts with an empty feature set and evaluates all sets containing one feature. After this it selects the one with the best performance and evaluates all sets with two features of which one is the best single feature. Backward sequential selection starts with all features and evaluates all sets with one feature less. It will selects the one with the best performance and then examines all feature sets which can be derived from this one by removing one feature. Both methods continue adding or removing a feature until they cannot improve the performance.
Forward and backward sequential selection are a variant of hill-climbing, a well-known search technique in artificial intelligence. As with hill-climbing, a disadvantage of these methods is that they can get stuck in local optima, in this case a non-optimal feature set which cannot be improved with the method used. In order to minimize the influence of local optima, we use a combination of the two methods when examining feature sets: bidirectional hill-climbing [Caruana and Freitag(1994)]. The idea here is to apply both adding a feature and removing a feature at each point in the feature space. This enables the feature selection method to backtrack from nonoptimal choices. In order to keep processing times down we will start with an empty feature list just like in forward sequential selection.